|
|
|
@@ -0,0 +1,262 @@ |
|
|
|
--- |
|
|
|
title: Data Collection Process |
|
|
|
subtitle: Differentiators Data | NC Campaign Finance Data Project |
|
|
|
author: Garrick Aden-Buie |
|
|
|
format: |
|
|
|
html: |
|
|
|
embed-resources: true |
|
|
|
|
|
|
|
editor: |
|
|
|
render-on-save: true |
|
|
|
|
|
|
|
execute: |
|
|
|
echo: false |
|
|
|
--- |
|
|
|
|
|
|
|
```{r setup} |
|
|
|
#| include: false |
|
|
|
|
|
|
|
pkgload::load_all(here::here("collect")) |
|
|
|
|
|
|
|
library(ggplot2) |
|
|
|
theme_set(theme_minimal(14, base_family = "Source Sans Pro")) |
|
|
|
|
|
|
|
targets::tar_config_set(store = here::here("collect/_targets")) |
|
|
|
``` |
|
|
|
|
|
|
|
## Reports by Year |
|
|
|
|
|
|
|
The campaign finance data gathering begins by collecting a table with the list of all quarterly or semi-annual reports filed by committees in the NC SBOE system by reporting year. |
|
|
|
The NC SBOE system allows you to search for reports by year and report type, |
|
|
|
which I use to construct a URL that lists all reports of a given type for a given year. |
|
|
|
|
|
|
|
::: {layout="[ [1,1] ]"} |
|
|
|
|
|
|
|
```{r} |
|
|
|
shiny::selectInput("year", "Year", choices = 2016:2023, selected = 2022, selectize = FALSE) |
|
|
|
``` |
|
|
|
|
|
|
|
```{r} |
|
|
|
report_choices <- c( |
|
|
|
"Mid-Year Semi-Annual Report" = "RPMYSA", |
|
|
|
"Year-End Semi-Annual Report" = "RPYESA", |
|
|
|
"1st Quarter Report" = "RPQTR1", |
|
|
|
"2nd Quarter Report" = "RPQTR2", |
|
|
|
"3rd Quarter Report" = "RPQTR3", |
|
|
|
"4th Quarter Report" = "RPQTR4" |
|
|
|
) |
|
|
|
shiny::selectInput("report_type", "Report", choices = report_choices, selected = "RPQTR1", selectize = FALSE) |
|
|
|
``` |
|
|
|
|
|
|
|
::: |
|
|
|
|
|
|
|
```{r} |
|
|
|
epoxy::ui_epoxy_whisker("reports_by_year", "<p><a href=\"https://cf.ncsbe.gov/CFDocLkup/DocumentResult/?year={{year}}&reports=%27{{report_type}}%27\">https://cf.ncsbe.gov/CFDocLkup/DocumentResult/?year={{year}}&reports=%27{{report_type}}%27</a></p>") |
|
|
|
``` |
|
|
|
|
|
|
|
```{js} |
|
|
|
function initApp () { |
|
|
|
const initData = { |
|
|
|
reports_by_year: { |
|
|
|
year: () => document.getElementById('year').value, |
|
|
|
report_type: () => document.getElementById('report_type').value |
|
|
|
} |
|
|
|
} |
|
|
|
|
|
|
|
const sendUpdatesToEpoxy = (outputId) => { |
|
|
|
const data = {...initData[outputId]} |
|
|
|
Object.keys(data).forEach(inputId => { |
|
|
|
data[inputId] = data[inputId]() |
|
|
|
}) |
|
|
|
EpoxyMustache.update_all({ [outputId]: data }) |
|
|
|
} |
|
|
|
|
|
|
|
Object.keys(initData).forEach(outputId => { |
|
|
|
sendUpdatesToEpoxy(outputId) |
|
|
|
|
|
|
|
Object.keys(initData[outputId]).forEach(inputId => { |
|
|
|
document |
|
|
|
.getElementById(inputId) |
|
|
|
.addEventListener('input', () => sendUpdatesToEpoxy(outputId)) |
|
|
|
}) |
|
|
|
}) |
|
|
|
} |
|
|
|
|
|
|
|
initApp() |
|
|
|
``` |
|
|
|
|
|
|
|
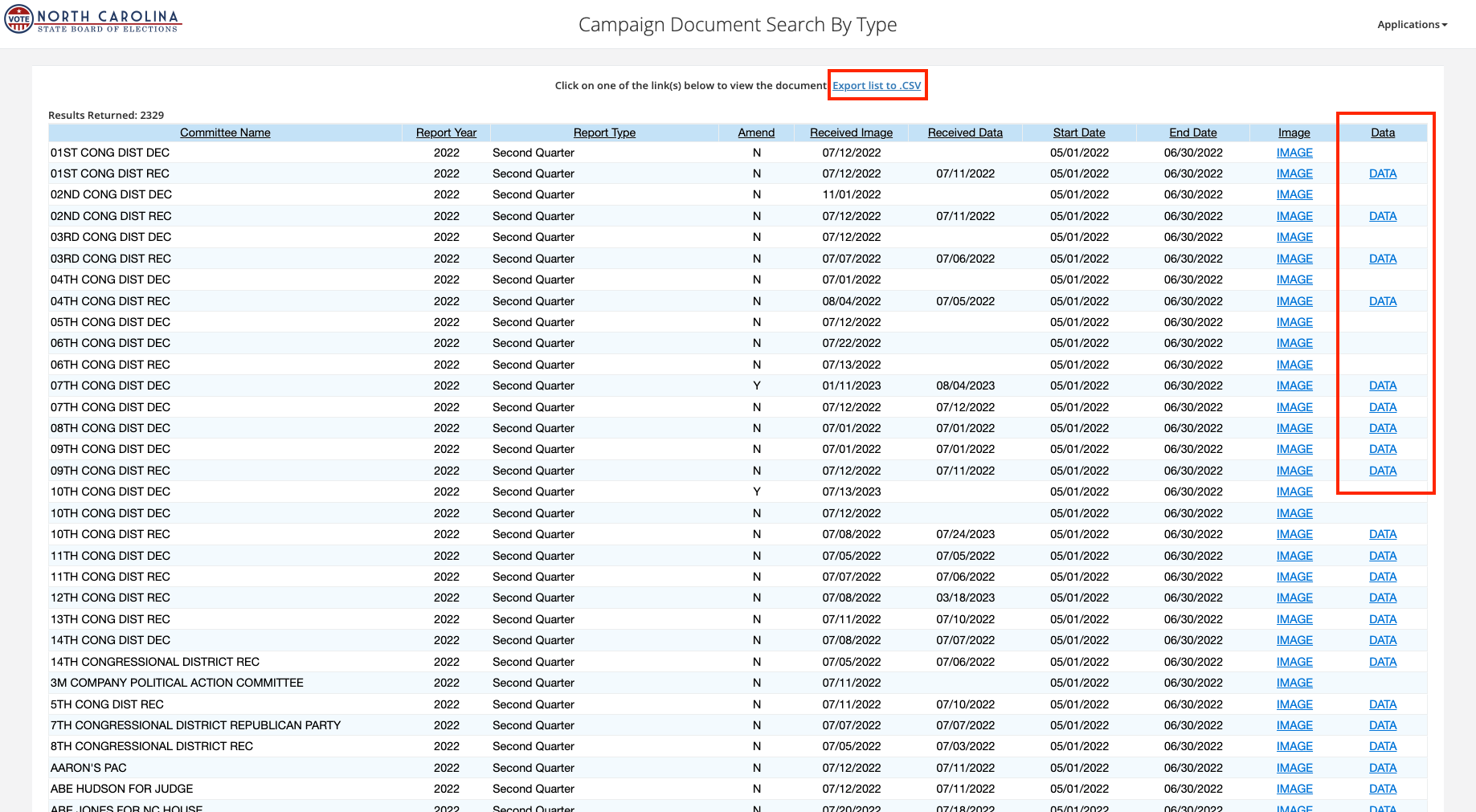
An individual link leads us to a master list of every report type, |
|
|
|
say _2nd Quarter Report_, |
|
|
|
filed in a year, e.g. 2022. |
|
|
|
This table includes links to the actual report in the **Data** column on the right, |
|
|
|
as well as a link to download the table as a `.csv` file via |
|
|
|
the _Export list to .csv_ link at the top of the page. |
|
|
|
|
|
|
|
](nc-sboe-cf-search-by-year-report.png) |
|
|
|
|
|
|
|
Unfortunately, |
|
|
|
the table that you get in the CSV does not include the link to the actual report, |
|
|
|
instead that field includes only the word `DATA` in place of the link. |
|
|
|
Furthermore, neither the CSV table nor the table displayed on the web page |
|
|
|
include the actual report ID, although it's used to construct the URLs in the **DATA** links. |
|
|
|
|
|
|
|
To get around these limitations, |
|
|
|
I discovered that the source data for the displayed table is included in the HTML file |
|
|
|
when you view the page source |
|
|
|
(right click anywhere on the page and choose "View Page Source"). |
|
|
|
Somewhere in the middle of the file is a bit of JavaScript that starts with |
|
|
|
`var data = [ ...`. |
|
|
|
This is essentially a JSON representation of the table data, |
|
|
|
and I could extract and read it into a table format. |
|
|
|
This table is actually very well formatted and importantly includes the bare report id |
|
|
|
as well as the committee's SBOE ID. |
|
|
|
|
|
|
|
```{r} |
|
|
|
# targets::tar_config_get("store") |
|
|
|
doc_list <- tar_read(doc_list) |> select(-tar_group) |
|
|
|
``` |
|
|
|
|
|
|
|
By scraping the table source data from every report list for years from 2016 through 2023, |
|
|
|
and for every available report type, |
|
|
|
I was able to put together a master list of every report of interest filed in the NC SBOE system. |
|
|
|
We found `r epoxy::epoxy("{.comma nrow(doc_list)}")` reports in total; |
|
|
|
here's a small preview of the values we have in this table: |
|
|
|
|
|
|
|
```{r} |
|
|
|
glimpse(doc_list) |
|
|
|
``` |
|
|
|
|
|
|
|
Looking at the total reports by report type and year shows a predictable pattern: |
|
|
|
on the whole, quarterly reports are filed in election (even) years, |
|
|
|
and semi-annual reports are filed in non-election (odd) years. |
|
|
|
There are also a few exceptions to this pattern, |
|
|
|
where a small number of semi-annual reports are filed in even years, |
|
|
|
and a larger but relatively small number of quarterly reports are filed in odd years. |
|
|
|
|
|
|
|
```{r} |
|
|
|
doc_names_levels <- c( |
|
|
|
paste(c("First", "Second", "Third", "Fourth"), "Quarter"), |
|
|
|
"Mid Year Semi-Annual", |
|
|
|
"Year End Semi-Annual" |
|
|
|
) |
|
|
|
|
|
|
|
doc_list |> |
|
|
|
mutate(doc_name = factor(doc_name, doc_names_levels)) |> |
|
|
|
ggplot() + |
|
|
|
aes(x = year) + |
|
|
|
geom_bar() + |
|
|
|
labs(x = NULL, y = NULL, title = "Number of Reports by Year and Report Type") + |
|
|
|
facet_wrap(~ doc_name, ncol = 2) |
|
|
|
``` |
|
|
|
|
|
|
|
## Reports by Committee |
|
|
|
|
|
|
|
The next step is to collect the actual report data for each of the reports in our master list. |
|
|
|
Fortunately, if we can use the `sboe_id` and `report_id` from the previous step |
|
|
|
to jump straight to the report page in the NC SBOE system. |
|
|
|
Here's an example taken at random from John Bell's reports: |
|
|
|
|
|
|
|
```{r} |
|
|
|
john_bell <- "STA-8S285O-C-001" |
|
|
|
|
|
|
|
jb_report_detail_url <- |
|
|
|
doc_list |> |
|
|
|
filter(sboe_id == john_bell, report_id == "164085") |> |
|
|
|
mutate( |
|
|
|
export_url = req_report_detail(report_id, "all")$url, |
|
|
|
url = glue::glue("https://cf.ncsbe.gov/CFOrgLkup/ReportDetail/?RID={report_id}&TP=ALL") |
|
|
|
) |
|
|
|
``` |
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
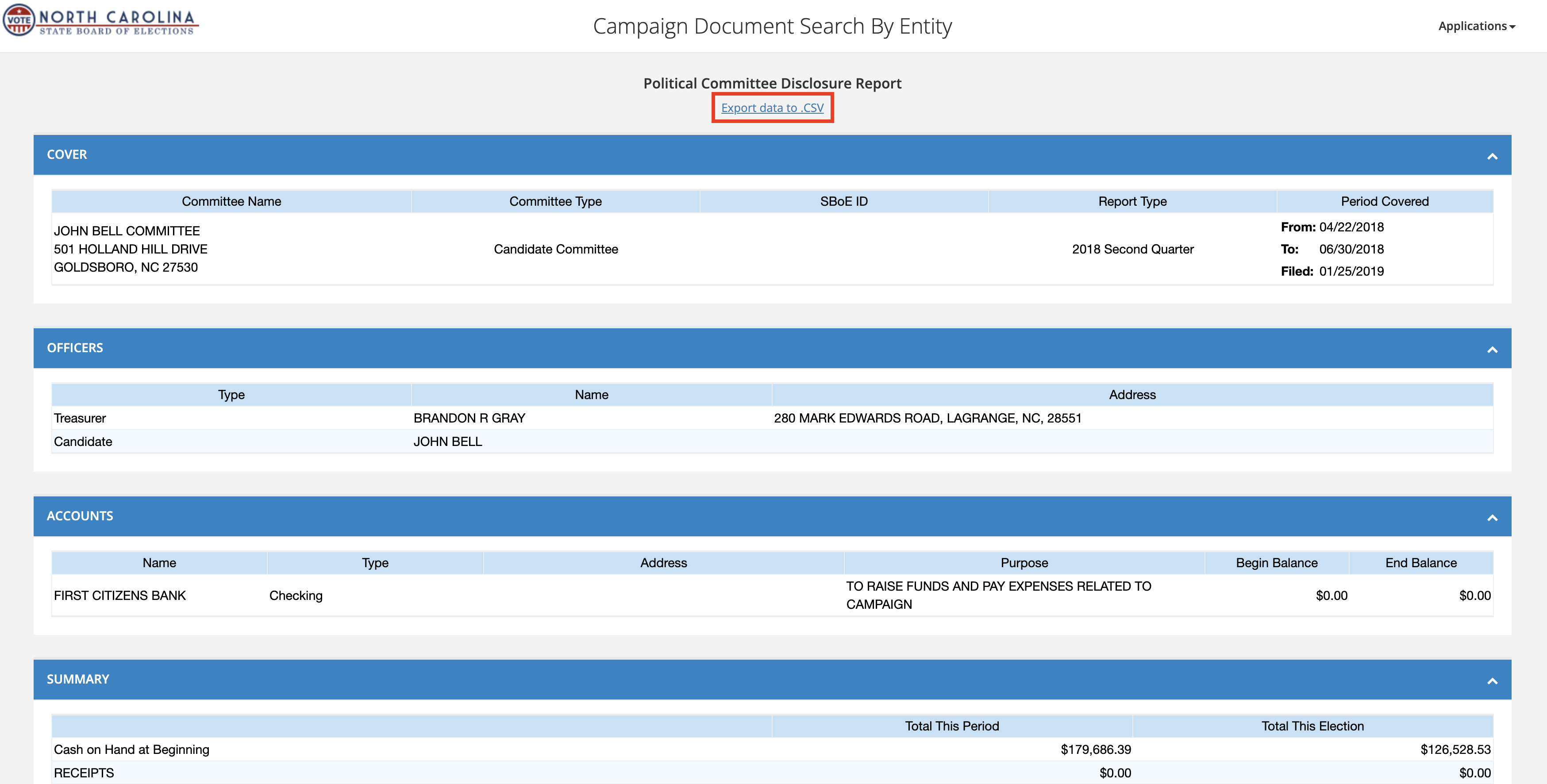
This single page _appears_ to have all of the data we want in one place, |
|
|
|
and it even has an _Export data to .csv_ link at the top of the page. |
|
|
|
The format of that exported data is a little unusual -- |
|
|
|
it's not really a CSV file but instead a text file with several CSV files concatenated together. |
|
|
|
Here's what you get when you download the export linked to in the above screenshot: |
|
|
|
|
|
|
|
```{r} |
|
|
|
htmltools::withTags( |
|
|
|
.noWS = c("outside", "inside"), |
|
|
|
div( |
|
|
|
class = "card mb-2", |
|
|
|
div(class = "card-header", paste0(jb_report_detail_url$report_id, ".txt")), |
|
|
|
div( |
|
|
|
class = "card-body", |
|
|
|
style = htmltools::css(maxHeight = "300px", overflowY = "scroll"), |
|
|
|
pre(code(paste(readLines(jb_report_detail_url$export_url), collapse = "\n"))) |
|
|
|
) |
|
|
|
) |
|
|
|
) |
|
|
|
``` |
|
|
|
|
|
|
|
## Receipts and Expenditures |
|
|
|
|
|
|
|
The full report text (a.k.a. 7 CSV files in a trench coat) |
|
|
|
is _so so close_ to what we want, |
|
|
|
but at scale it doesn't work out that well. |
|
|
|
It appears that the NC SBOE hand-rolled their CSV exports |
|
|
|
and unfortunately don't create properly-formatted CSV files in some edge cases. |
|
|
|
These edge cases are mostly places where the SBOE would have reasonably expected users to enter a short text description, |
|
|
|
and instead users have entered longer text with commas and newlines, |
|
|
|
which break the CSV format. |
|
|
|
|
|
|
|
These "all report sections" text file exports are worth downloading |
|
|
|
because they include several tables that we'd want to collect anyway, |
|
|
|
and we want to reduce the number of files and HTML pages we have to request from the NC SBOE system. |
|
|
|
|
|
|
|
For the two most important tables, |
|
|
|
`receipts` and `expenditures`, |
|
|
|
it turns out that the "all reports page" listed above |
|
|
|
actually calls out to two unlisted, internal API endpoints |
|
|
|
to create the Receipts and Expenditures tables. |
|
|
|
These endpoints return JSON data which is guaranteed to be correctly formatted |
|
|
|
and easier to process into a table format. |
|
|
|
|
|
|
|
They say _there's no such thing as a free lunch_, |
|
|
|
and apparently this rule also applies to the NC SBOE campaign finance website. |
|
|
|
These API endpoints return at most 300 records at a time, |
|
|
|
meaning that for most reports we have to make multiple requests |
|
|
|
to gather all of the report data. |
|
|
|
|
|
|
|
Here are two examples of the URLs I used to get the receipts and expenditures data for John Bell's report: |
|
|
|
|
|
|
|
```{r} |
|
|
|
url_receipts_json <- req_report_receipts(jb_report_detail_url$report_id, 0) |
|
|
|
url_expenditures_json <- req_report_expenditures(jb_report_detail_url$report_id, 0) |
|
|
|
``` |
|
|
|
|
|
|
|
* [Receipts for report `r jb_report_detail_url$report_id`, page 1](`r url_receipts_json$url`) |
|
|
|
* [Expenditures for report `r jb_report_detail_url$report_id`, page 1](`r url_expenditures_json$url`) |
|
|
|
|
|
|
|
## Final Set of Files |
|
|
|
|
|
|
|
In the end, there are three files that we download directly from the NC SBOE system |
|
|
|
for each report: |
|
|
|
|
|
|
|
1. The "all reports" text file export |
|
|
|
2. The receipts JSON data, saved as a (correctly-formatted) CSV file |
|
|
|
3. The expenditures JSON data, saved as a CSV file |
|
|
|
|
|
|
|
Locally, I've organized these into a directory structure that looks like this, |
|
|
|
where `` `r john_bell` `` is John Bell's committee's SBOE ID: |
|
|
|
|
|
|
|
``` |
|
|
|
data-raw/reports/STA-8S285O-C-001 |
|
|
|
├── all |
|
|
|
│ ├── ... |
|
|
|
│ ├── 164085_2019-01-25.txt |
|
|
|
│ └── ... |
|
|
|
├── expenditures |
|
|
|
│ ├── ... |
|
|
|
│ ├── 164085_2019-01-25_expenditures.csv |
|
|
|
│ └── ... |
|
|
|
└── receipts |
|
|
|
├── ... |
|
|
|
├── 164085_2019-01-25_receipts.csv |
|
|
|
└── .... |
|
|
|
``` |
|
|
|
|
|
|
|
The end result is a complete set of files for every quarterly or semi-annual campaign finance report |
|
|
|
filed with the NC SBOE. |


{kind=link}
{kind=link}